Redis的安装
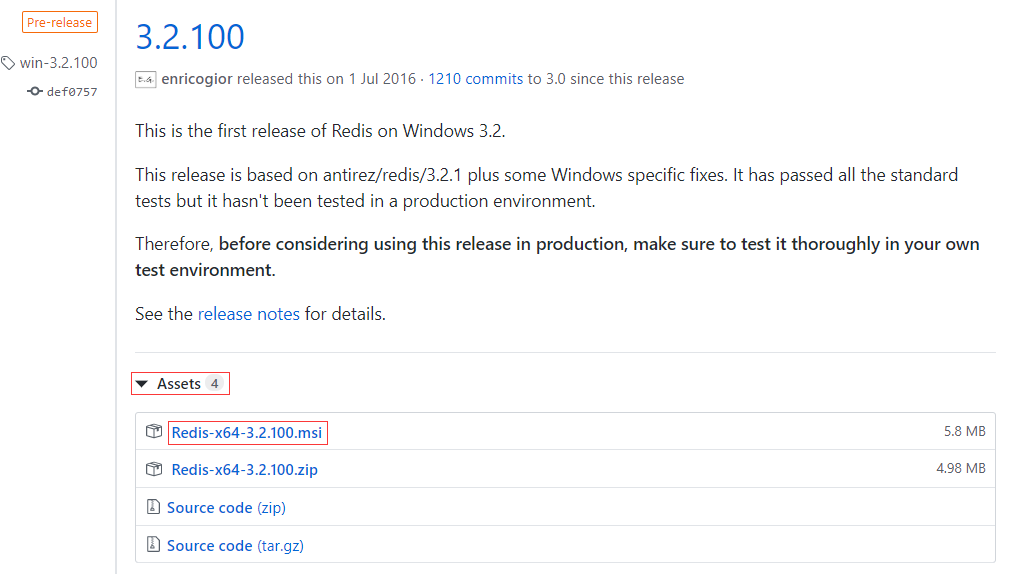
1. Redis 的下载
- 下载网址
https://github.com/microsoftarchive/redis/releases
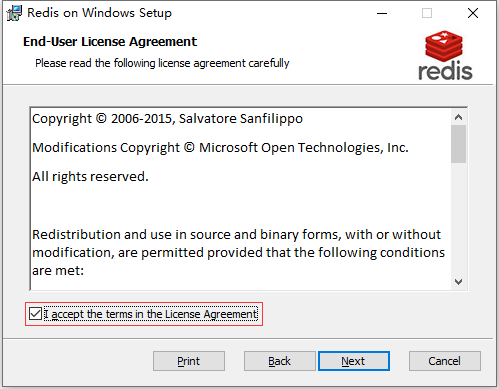
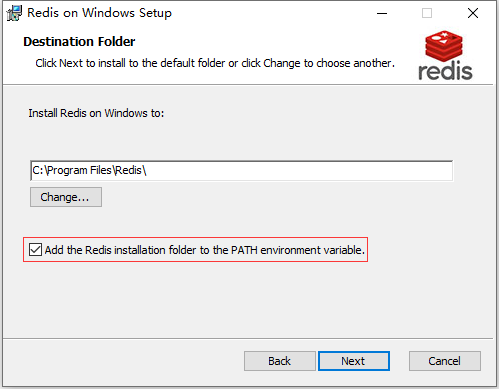
2. Redis 的安装
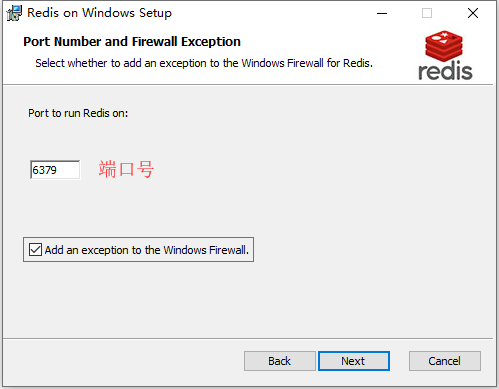
3. 启动 Redis 服务端软件
- 服务端软件的作用: 解析客户端发送过来的指令对内存中写入或读取缓存数据
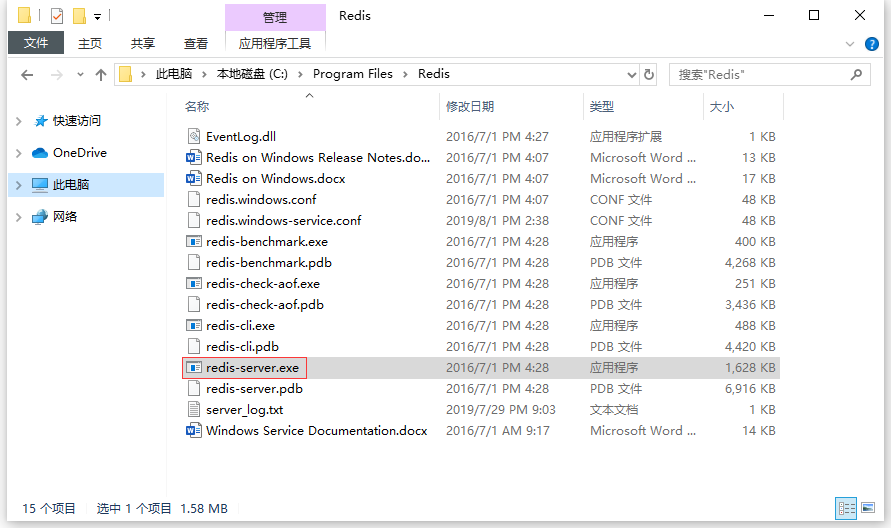
- 找到 Redis 的安装目录然后执行 redis-server.exe 启动 Redis
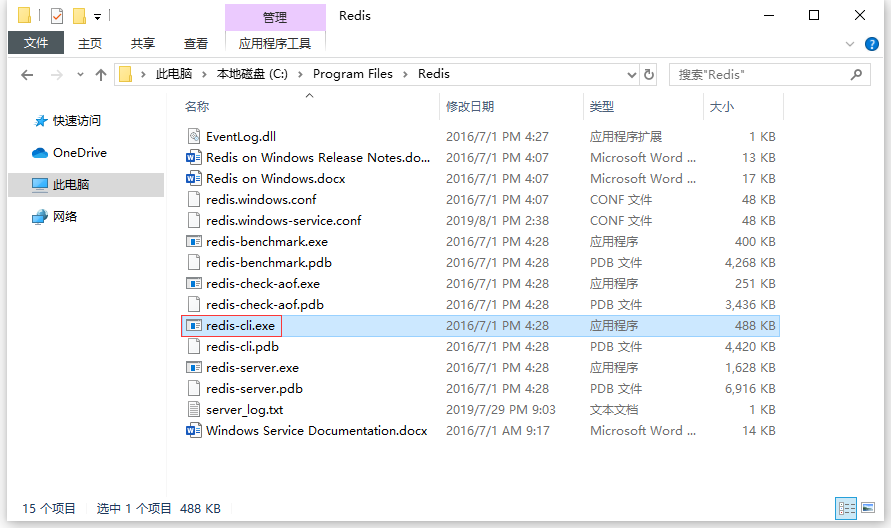
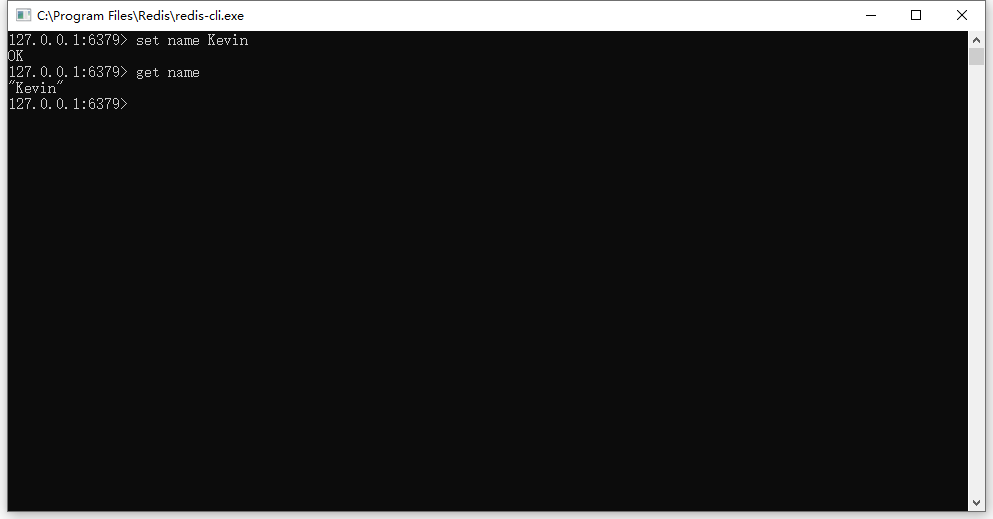
4. Redis 的客户端软件 -> redis-cli.exe
- 客户端软件的作用: 向服务端发送指令,从而对缓存数据进行操作
- redis-cli.exe 用于设置缓存
Redis的介绍
1. 为什么要使用缓存
在Django中,当用户请求到达视图后,视图会先从数据库提取数据放到模板中进行动态渲染,渲染后的结果就是用户看到的网页。如果用户每次请求都从数据库提取数据并渲染,将极大降低性能,不仅服务器压力大,而且客户端也无法即时获得响应。如果能将渲染后的结果放到速度更快的缓存中,每次有请求过来,先检查缓存中是否有对应的资源,如果有,直接从缓存中取出来返回响应,节省取数据和渲染的时间,不仅能大大提高系统性能,还能提高用户体验
2. Redis 的介绍
- Redis 就是一个软件 和 Mysql 类似,都是用于存储数据
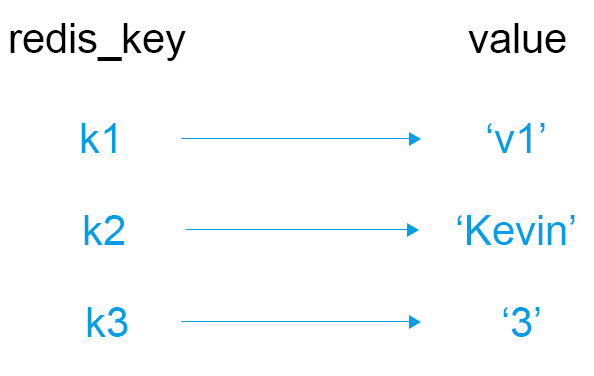
- Redis 是一个非关系型数据库(即: 以键值对的形式存储数据)
- Redis 所存储的都是字符串,不能储存数字(就算在开发的时候value所填写的是数字,那么 redis 模块也会将数字转换为字符串再进行存储)
- Redis 可以被多台机器连接,然后操作缓存中的数据(和Mysql一样可以被别的机器连接)
3. Redis 和 MySQL 的区别
- MySQL是一个软件,帮助开发者对一台机器的硬盘进行操作
- Redis是一个软件,帮助开发者对一台机器的内存进行操作
4. 使用 Redis 的好处
- 速度快,提高效率,因为 Redis 的数据是存放在内存中的,而Mysql是存放在磁盘中的(因为使用Mysql的时候,需用进行打开读写操作,所以要比 Redis 直接从内存中获取数据要慢)
- 支持丰富的数据类型: string(字符串),list(列表),set(集合),sorted set(有序集合),hash(字典)
- 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
- 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
5. 使用 Redis 的缺点
- 服务器一旦崩溃,储存在内存中的缓存数据就会没有
6. Redis 相比 Memcached有哪些优势
- (Memcached的说明: Memcached 的功能和 redis 是一样的,用于缓存数据)
- Memcached 所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型
- redis的速度比Memcached快很多
- redis可以持久化其数据 -> 将数据保存到磁盘上
7. redis 和 Memcached 的区别
- 存储方式
- Memecache 把数据全部存在内存之中,断电后会全部丢失,数据不能超过内存大小
- Redis有部份存在硬盘上,这样能保证数据的持久性
- 数据类型
- Memecache 只支持简单的字符串
- Redis 支持丰富的数据类型: string(字符串),list(列表),set(集合),sorted set(有序集合),hash(字典)
- 存储空间的大小
- Memecache 最大只有 1M
- Redis 最大可以达到 1G
8. redis 的使用场景
- 通俗理解: 临时状态,且频繁修改状态,如: 购物车
- 会话缓存(Session Cache)
- 最常用的一种使用Redis的情景是会话缓存(session cache)。用Redis缓存会话比其他存储(如Memcached)的优势在于:Redis提供持久化。当维护一个不是严格要求一致性的缓存时,如果用户的购物车信息全部丢失,大部分人都会不高兴的,现在,他们还会这样吗?幸运的是,随着 Redis 这些年的改进,很容易找到怎么恰当的使用Redis来缓存会话的文档。甚至广为人知的商业平台Magento也提供Redis的插件
- 全页缓存(FPC)
- 除基本的会话token之外,Redis还提供很简便的FPC平台。回到一致性问题,即使重启了Redis实例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降,这是一个极大改进,类似PHP本地FPC。再次以Magento为例,Magento提供一个插件来使用Redis作为全页缓存后端。此外,对WordPress的用户来说,Pantheon有一个非常好的插件 wp-redis,这个插件能帮助你以最快速度加载你曾浏览过的页面。
- 队列
- Reids在内存存储引擎领域的一大优点是提供 list 和 set 操作,这使得Redis能作为一个很好的消息队列平台来使用。Redis作为队列使用的操作,就类似于本地程序语言(如Python)对 list 的 push/pop 操作
- 如果你快速的在Google中搜索“Redis queues”,你马上就能找到大量的开源项目,这些项目的目的就是利用Redis创建非常好的后端工具,以满足各种队列需求。例如,Celery有一个后台就是使用Redis作为broker,你可以从这里去查看
- 排行榜/计数器
- Redis在内存中对数字进行递增或递减的操作实现的非常好。集合(Set)和有序集合(Sorted Set)也使得我们在执行这些操作的时候变的非常简单,Redis只是正好提供了这两种数据结构。所以,我们要从排序集合中获取到排名最靠前的10个用户–我们称之为“user_scores”,我们只需要像下面一样执行即可:
- 当然,这是假定你是根据你用户的分数做递增的排序。如果你想返回用户及用户的分数,你需要这样执行:
- ZRANGE user_scores 0 10 WITHSCORES
- Agora Games就是一个很好的例子,用Ruby实现的,它的排行榜就是使用Redis来存储数据的,你可以在这里看到
- 发布/订阅
- 发布/订阅的使用场景确实非常多。我已看见人们在社交网络连接中使用,还可作为基于发布/订阅的脚本触发器,甚至用Redis的发布/订阅功能来建立聊天系统!(不,这是真的,你可以去核实)
Python 安装 Redis
pip3 install redis -i https://pypi.douban.com/simple # 使用豆瓣的镜像
- 安装 redis 最好同时安装上 hiredis
- hiredis 的作用: 提升 redis 的使用性能
- 如果已经安装了hiredis模块,redis 默认会尝试使用HiredisParser,否则会使用PythonParser
pip3 install hiredis -i https://pypi.douban.com/simple # 使用豆瓣的镜像
连接 Redis Server
1. 方式一
- redis.Redis(host='ip地址', port=端口号, password='密码')
- 如果 host 和 port 不传,默认使用本地的ip和端口
- 如果没有密码可以不用填写 password 参数
# 固定写法
import redis
r = redis.Redis(host='ip地址', port=端口号,password='密码')
# r = redis.Redis() # 如果 host 和 port 不传,默认使用本地的ip和端口
# 使用 r 对象操作缓存中的数据
import redis
r = redis.Redis(host='10.211.55.4', port=6379, password='123')
# r = redis.Redis() # 如果 host 和 port 不传,默认使用本地的ip和端口
# 使用 r 对象操作缓存中的数据
- decode_responses 参数
- decode_responses 参数默认值 Flase
- decode_responses 参数 -> 是否自动进行解码,因为从缓存中获取到的值是 Bytes 类型的需要手动进行解码,当 decode_responses=True 的时候,在获取缓存中的值的时候会自动进行解码
import redis
r = redis.Redis(host='10.211.55.4', port=6379, password='123', decode_responses=True)
# r = redis.Redis(decode_responses=True)
2. 方式二
- 连接池 -> 推荐使用
- 连接池: 避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池
- 注意: 连接池只创建一次,使用模块的单例模式方式创建连接池,避免在导入模块的时候重复创建连接池,如果每一次使用redis都创建一个连接池,那么性能就会和方式一一样
- 固定写法
# redis_pool.py
import redis
# 创建连接池
POOL = redis.ConnectionPool(host='ip地址', port=端口号, password='密码', max_connections=最大连接数) # 注意: 连接池只创建一次,使用模块的单例模式方式创建连接池,避免在导入模块的时候重复创建连接池
# POOL = redis.ConnectionPool() # 如果 host 和 port 不传,默认使用本地的ip和端口
# 如果没有密码可以不用填写 password 参数
# 如果 max_connections 不传,默认使用redis连接池的最大连接数
# xxx.py
import redis
from redis_pool import POOL
# 去连接池中获取连接
r = redis.Redis(connection_pool=POOL)
# 使用 r 对象操作缓存中的数据
- 实例
# redis_pool.py
import redis
# 创建连接池
POOL = redis.ConnectionPool(host='10.211.55.4', port=6379, password='123', max_connections=1000) # 注意: 连接池只创建一次,使用模块的单例模式方式创建连接池,避免在导入模块的时候重复创建连接池
# POOL = redis.ConnectionPool() # 如果 host 和 port 不传,默认使用本地的ip和端口
# 如果没有密码可以不用填写 password 参数
# 如果 max_connections 不传,默认使用redis连接池的最大连接数
# xxx.py
import redis
from redis_pool import POOL
# 去连接池中获取连接
r = redis.Redis(connection_pool=POOL)
# 使用 r 对象操作缓存中的数据
- decode_responses 参数
- decode_responses 参数默认值 Flase
- decode_responses 参数 -> 是否自动进行解码,因为从缓存中获取到的值是 Bytes 类型的需要手动进行解码,当 decode_responses=True 的时候,在获取缓存中的值的时候会自动进行解码
# redis_pool.py
import redis
# 创建连接池
POOL = redis.ConnectionPool(host='10.211.55.4', port=6379, password='123', max_connections=1000, decode_responses=True) # 注意: 连接池只创建一次,使用模块的单例模式方式创建连接池,避免在导入模块的时候重复创建连接池
# POOL = redis.ConnectionPool(decode_responses=True)
# xxx.py
import redis
from redis_pool import POOL
r = redis.Redis(connection_pool=POOL)
Redis 的使用
注意: 连接池一定要使用模块的单例模式方式创建,否则性能方面和上面的方式一的性能是一样的,这里只是为了方便才写在一块的
# 日常开发的时候连接池一定要使用模块的单例模式方式创建,在这里只是为了方便笔记才写在一块的
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
1. String(字符串)类型的操作
- set(name, value, ex=None, px=None, nx=False, xx=False)
- 添加或修改缓存(包含过期时间)
- 参数:
- name: 缓存名
- value: 需要缓存的字符串类型的值
- ex: 过期时间(秒)
- px: 过期时间(毫秒)
- nx: 如果值为 True,当 name 不存在的时候,当前set操作才会执行
- xx: 如果值为 True,当 name 存在的时候,当前set操作才会执行
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.set(name='username', value='Kevin', ex=5)
- setnx(name, value)
- 添加缓存(不包含过期时间)
- 只有 name 不存在时,才添加 value 等于字符串类型的缓存
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.setnx(name='username', value='Kevin')
- setex(name, value, time)
- 添加或修改过期时间单位为秒的缓存(包含过期时间)
- 参数:
- name: 缓存名
- value: 需要缓存的字符串类型的值
- time: 过期时间(数字秒 或 timedelta对象)
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.setex(name='username', value='Kevin', time=5)
- psetex(name, time_ms, value)
- 添加或修改过期时间单位为毫秒缓存(包含过期时间)
- 参数:
- name: 缓存名
- value: 需要缓存的字符串类型的值
- time_ms: 过期时间(数字毫秒 或 timedelta对象)
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.psetex(name='username', value='Kevin', time_ms=5000)
- mset(mapping)
- 批量设置缓存(不包含过期时间)
- 参数:
- mapping: 字典,如:{'k1':'v1', 'k2': 'v2'}
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.mset({'k1': 'v1', 'k2': 'v2'})
- msetnx(mapping)
- 批量设置缓存(不包含过期时间),如果该缓存存在则不进行添加
- 参数:
- mapping: 字典,如:{'k1':'v1', 'k2': 'v2'}
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.msetnx({'k1': 'v3', 'k2': 'v4'})
- get(name)
- 获取缓存中的值,且 value 的类型为 String(字符串)
- 当 decode_responses=False/decode_responses参数没有设置 的时候获取到的值是 bytes 类型
import redis
pool = redis.ConnectionPool()
r = redis.Redis(connection_pool=pool)
username = r.get('username')
print(username) # b'Kevin'
- 当 decode_responses=True 的时候获取到的值是经过解码后的值(即: 字符串类型)
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
username = r.get('username')
print(username) # Kevin
- mget(keys, *args)
- 批量获取缓存中的值,且 value 的类型为 String(字符串)
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 写法一
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r_value_list = r.mget(['k1', 'k2'])
print(r_value_list) # ['v1', 'v2']
- 写法二
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r_value_list = r.mget('k1', 'k2')
print(r_value_list) # ['v1', 'v2']
- getset(name, value)
- 设置新值并返回原来的值
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
old_value = r.getset(name='username', value='Yeung')
print(old_value) # Kevin
- getrange(key, start, end)
- 切片
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 参数:
- key: 缓存中key的名字
- start: 切片起始值
- end: 切片结束值
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
result = r.getrange(key='username', start=0, end=1)
print(result) # 原本的值: Kevin,切片后得到的值: Ke
- setrange(name, offset, value)
- 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加)
- 参数:
- name: 缓存名
- offset: 字符串的索引,字节(一个汉字3个字节)
- value: 需要插入的值
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.setrange(name='username', offset=2, value='_插入的值_')
print(r.get('username')) # 原本的值: Kevin,插值后: Ke_插入的值_
- strlen(name)
- 返回name对应缓存的值的字节长度(一个汉字3个字节)
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
english_length = r.strlen('username')
print(english_length) # 值: Kevin,长度: 5
chinese_length = r.strlen('chinese')
print(chinese_length) # 值: 中文,长度: 6
- incr(name, amount)
- 整数自增,当name不存在时,则创建name=amount,否则,进行整数自增
- 需要自增的value必须是整数
- 参数:
- name: 缓存名
- amount: 每次自增的数量(即: 每次添加的数量),必须是整数
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.incr(name='age', amount=2)
print(r.get('age')) # 原本的值: 1,自增后的值: 3
- incrbyfloat(name, amount)
- 浮点数自增,当name不存在时,则创建name=amount,否则,进行浮点数自增
- 需要自增的value可以是整数或浮点数
- 参数:
- name: 缓存名
- amount: 每次自增的数量(即: 每次添加的数量),可以是整数或浮点数
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.incrbyfloat(name='age', amount=2.5)
print(r.get('age')) # 原本的值: 1,自增后的值: 3.5
- decr(name, amount=1)
- 整数自减,当name不存在时,则创建name=amount,否则,进行整数自减
- 需要自减的value必须是整数
- 参数:
- name: 缓存名
- amount: 每次自减的数量(即: 每次减少的数量),必须是整数
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.decr(name='age', amount=2)
print(r.get('age')) # 原本的值: 2,自增后的值: 0
- append(key, value)
- 在指定的缓存值后面追加内容
- 参数
- key: 缓存中key的名字
- value: 需要追加的内容
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.append(key='username', value='追加的内容')
print(r.get('username')) # 原本的值: Kevin,追加内容后的值: Kevin追加的内容
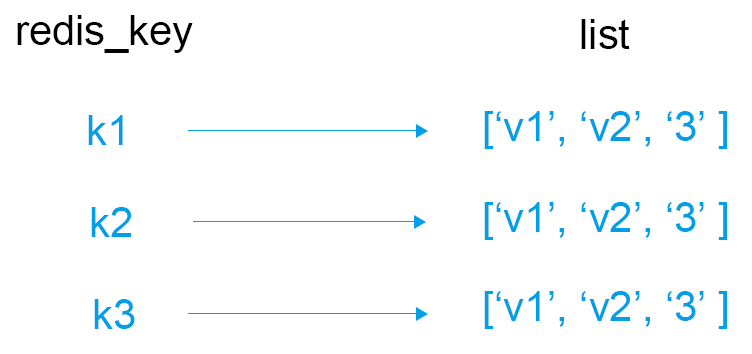
2. List(列表)类型的操作
- lpush(name, *values)
- 在name对应的list中添加元素,每个新的元素都添加到列表的最左边 -> 相当于创建一个列表
- 参数:
- name: 缓存名
- values: 要添加的元素,可以接收多个值
- 写法一
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.lpush('books', '三国演义', '红楼梦', '西游记', '水浒传')
print(r.lrange('books', 0, -1)) # ['水浒传', '西游记', '红楼梦', '三国演义']
- 写法二
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
books = ['三国演义', '红楼梦', '西游记', '水浒传']
r.lpush('books', *books)
print(r.lrange('books', 0, -1)) # ['水浒传', '西游记', '红楼梦', '三国演义']
- rpush(name, *values)
- 在name对应的list中添加元素,每个新的元素都添加到列表的最右边 -> 相当于创建一个列表
- 参数:
- name: 缓存名
- values: 要添加的元素,可以接收多个值
- 写法一
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.rpush('books', '三国演义', '红楼梦', '西游记', '水浒传')
print(r.lrange('books', 0, -1)) # ['三国演义', '红楼梦', '西游记', '水浒传']
- 写法二
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
books = ['三国演义', '红楼梦', '西游记', '水浒传']
r.rpush('books', *books)
print(r.lrange('books', 0, -1)) # ['三国演义', '红楼梦', '西游记', '水浒传']
- lpushx(name, value)
- 在name对应的list中添加元素,只有当name已经存在时,值才会添加到列表的最左边
- 参数:
- name: 缓存名
- value: 要添加的元素,只能接收一个值
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.lpushx(name='books', value='三体')
print(r.lrange('books', 0, -1)) # 原本的值: ['三国演义', '红楼梦', '西游记', '水浒传'],添加新元素后的值: ['三体', '三国演义', '红楼梦', '西游记', '水浒传']
- rpushx(name, value)
- 在name对应的list中添加元素,只有当name已经存在时,值才会添加到列表的最右边
- 参数:
- name: 缓存名
- value: 要添加的元素,只能接收一个值
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.rpushx(name='books', value='三体')
print(r.lrange('books', 0, -1)) # 原本的值: ['三国演义', '红楼梦', '西游记', '水浒传'],添加新元素后的值: ['三国演义', '红楼梦', '西游记', '水浒传', '三体']
- llen(name)
- 获取name对应的list元素的个数
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
books_len = r.llen('books')
print(books_len) # 值: ['三国演义', '红楼梦', '西游记', '水浒传'],长度: 4
- linsert(name, where, refvalue, value)
- 在name对应的列表的某一个值前面或后面插入一个新值
- 如果要在某个值前后插入一个新值,且这某个值有重复,那么只会获取第一个,作为标杆值
- 参数:
- name: 缓存名
- where: BEFORE(之前)/ AFTER(之后)
- refvalue: 标杆值(即:列表中的值,在它前后插入数据),如果有相同的标杆值,那么只会获取第一个
- value: 需要插入的数据
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.linsert(name='books', where='BEFORE', refvalue='红楼梦', value='三体')
print(r.lrange('books', 0, -1)) # 原本的值: ['三国演义', '红楼梦', '红楼梦', '西游记', '水浒传'],添加新元素后的值: ['三国演义', '三体', '红楼梦', '红楼梦', '西游记', '水浒传']
- lset(name, index, value)
- 在name对应的list中的指定索引位置重新赋值
- 参数:
- name: 缓存名
- index: 索引
- value: 需要重新赋值的值
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.lset(name='books', index=1, value='三体')
print(r.lrange('books', 0, -1)) # 原本的值: ['三国演义', '红楼梦', '西游记', '水浒传'],添加新元素后的值: ['三国演义', '三体', '西游记', '水浒传']
- lrem(name, count, value)
- 在name对应的list中删除指定的值
- 参数:
- name: 缓存名
- value: 要删除的值
- count: 要删除的数量
- count > 0: 从表头开始向表尾搜索,移除 count 个与value值相等的元素
- count < 0: 从表尾开始向表头搜索,移除 count的绝对值 个与value值相等的元素
- count = 0: 移除表中所有与 value 相等的值
- count > 0: 从表头开始向表尾搜索,移除 count 个与value值相等的元素
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.lrem(name='books', count=2, value='三国演义') # count > 0,从表头开始向表尾搜索,移除 2 个与 '三国演义' 相等的值
print(r.lrange('books', 0, -1)) # 原本的值: ['三国演义', '红楼梦', '西游记', '三国演义', '水浒传', '三国演义'],移除相关元素后的值: ['红楼梦', '西游记', '水浒传', '三国演义']
- count < 0: 从表尾开始向表头搜索,移除 count的绝对值 个与value值相等的元素
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.lrem(name='books', count=-2, value='三国演义') # count < 0,从表尾开始向表头搜索,移除 2 个与 三国演义 相等的值
print(r.lrange('books', 0, -1)) # 原本的值: ['三国演义', '红楼梦', '西游记', '三国演义', '水浒传', '三国演义'],移除相关元素后的值: ['三国演义', '红楼梦', '西游记', '水浒传']
- count = 0: 移除表中所有与 value 相等的值
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.lrem(name='books', count=0, value='三国演义') # count = 0,移除表中所有与 三国演义 相等的值
print(r.lrange('books', 0, -1)) # 原本的值: ['三国演义', '红楼梦', '西游记', '三国演义', '水浒传', '三国演义'],移除相关元素后的值: ['红楼梦', '西游记', '水浒传']
- lpop(name)
- 删除指定列表的左边第一个元素(即: 列表的一个元素),返回值: 被删除的元素
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
del_book = r.lpop('books')
print(r.lrange('books', 0, -1)) # 原本的值: ['三国演义', '红楼梦', '西游记', '水浒传'],移除相关元素后的值: ['红楼梦', '西游记', '水浒传']
print(del_book) # 三国演义
- rpop(name)
- 删除指定列表的右边第一个元素(即: 列表的最后一个元素),返回值: 被删除的元素
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
del_book = r.rpop('books')
print(r.lrange('books', 0, -1)) # 原本的值: ['三国演义', '红楼梦', '西游记', '水浒传'],移除相关元素后的值: ['三国演义', '红楼梦', '西游记']
print(del_book) # 水浒传
- lindex(name, index)
- 在name对应的列表中根据索引获取列表中的元素
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 参数:
- name: 缓存名
- index: 索引
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
book = r.lindex(name='books', index=2)
print(book) # 西游记
- lrange(name, start, end)
- 切片
- 只有通过切片才能获取到缓存列表中的所有数据
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 参数:
- name: 缓存名
- start: 索引的起始位置
- end: 索引的结束位置
- 获取所有数据
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
all_data = r.lrange(name='books', start=0, end=-1)
print(all_data) # ['三国演义', '红楼梦', '西游记', '水浒传']
- 获取指定区域的数据
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
all_data = r.lrange(name='books', start=1, end=2)
print(all_data) # 所有的数据: ['三国演义', '红楼梦', '西游记', '水浒传'],切片后获取到的数据: ['红楼梦', '西游记']
- ltrim(name, start, end)
- 移除name对应列表不在 start-end 范围内的值
- 和lrange的区别: lrange不修改原列表直接返回切片的结果,ltrim 直接修改原列表
- 参数:
- name: 缓存名
- start: 索引的起始位置
- end: 索引的结束位置
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
all_data = r.ltrim(name='books', start=1, end=2)
print(all_data) # True
print(r.lrange('books', 0, -1)) # 所有的数据: ['三国演义', '红楼梦', '西游记', '水浒传'],移除后的数据: ['红楼梦', '西游记']
- rpoplpush(src, dst)
- 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边
- 参数:
- src: 要取数据的列表的name
- dst: 要添加数据的列表的name
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.rpoplpush(src='library1', dst='library2')
print(r.lrange('library1', 0, -1)) # 原本数据: ['book1_1', 'book1_2', 'book1_3'],执行 rpoplpush 后的数据: ['book1_1', 'book1_2']
print(r.lrange('library2', 0, -1)) # 原本数据: ['book2_1', 'book2_2', 'book2_3'],执行 rpoplpush 后的数据: ['book1_3', 'book2_1', 'book2_2', 'book2_3']
- blpop(keys, timeout)
- 移出并获取列表的第一个元素,如果列表没有元素就会进入阻塞直到等待超时或发现元素位置(如果没有设置 timeout 或者 timeout=0,那么当列表为空的时候就会阻塞着,直到列表有值)
- 返回值: 如果列表为空,返回 None,否则,返回一个列表,第一个元素: 本删除元素所属的name,第二元素: 被删除的值
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 参数:
- keys: 缓存名的集合
- timeout: 超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.rpush('list1', '一', '二', '三')
r.rpush('list2', '一', '二', '三')
print(r.blpop(keys=['list1', 'list2', 'list3'], timeout=2)) # ('list1', '一')
print(r.blpop(keys=['list1', 'list2', 'list3'], timeout=2)) # ('list1', '二')
print(r.blpop(keys=['list1', 'list2', 'list3'], timeout=2)) # ('list1', '三')
print(r.blpop(keys=['list1', 'list2', 'list3'], timeout=2)) # ('list2', '一')
print(r.blpop(keys=['list1', 'list2', 'list3'], timeout=2)) # ('list2', '二')
print(r.blpop(keys=['list1', 'list2', 'list3'], timeout=2)) # ('list2', '三')
print(r.blpop(keys=['list1', 'list2', 'list3'], timeout=2)) # None -> 因为 list3 为空
print(r.lrange('list1', 0, -1)) # []
print(r.lrange('list2', 0, -1)) # []
- brpoplpush(src, dst, timeout=0)
- 从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧,如果src的列表没有元素就会进入阻塞直到等待超时或发现元素位置(如果没有设置 timeout 或者 timeout=0,那么当列表为空的时候就会阻塞着,直到列表有值)
- 返回值: src 列表为空,返回None,否者,返回 src 列表被移除的最后一个元素
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 参数:
- src: 要取数据的列表的name
- dst: 要添加数据的列表的name
- 当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.rpush('library1', 'book1_1', 'book1_2', 'book1_3')
r.rpush('library2', 'book2_1', 'book2_2', 'book2_3')
print(r.brpoplpush(src='library1', dst='library2', timeout=2)) # book1_3
print(r.brpoplpush(src='library1', dst='library2', timeout=2)) # book1_2
print(r.brpoplpush(src='library1', dst='library2', timeout=2)) # book1_1
print(r.brpoplpush(src='library1', dst='library2', timeout=2)) # None
print(r.lrange('library1', 0, -1)) # []
print(r.lrange('library2', 0, -1)) # ['book1_1', 'book1_2', 'book1_3', 'book2_1', 'book2_2', 'book2_3']
- 自定义增量迭代
- 由于redis类库中没有提供对列表元素的增量迭代,如果想要循环name对应的列表的所有元素,那么就需要:
- 获取name对应的所有列表
- 循环列表
- 但是,如果列表非常大,那么就有可能在第一步时就将程序的内容撑爆,所有有必要自定义一个增量迭代的功能:
def list_iter(name):
"""
自定义redis列表增量迭代
:param name: redis中的name,即:迭代name对应的列表
:return: yield 返回 列表元素
"""
list_count = r.llen(name)
for index in range(list_count):
yield r.lindex(name, index)
# 使用
for item in list_iter('pp'):
print(item)
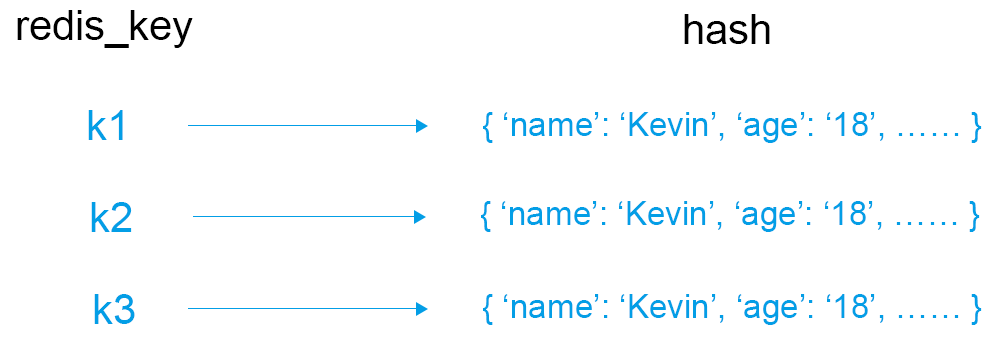
3.Hash(字典)类型的操作
- hset(name, key, value)
- 在name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
- 参数:
- name: 缓存名
- key: name对应的hash中的key
- value: name对应的hash中的value
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.hset(name='info', key='username', value='Kevin')
print(r.hgetall('info')) # {'username': 'Kevin'}
- hsetnx(name, key, value)
- 当name对应的hash中不存在当前key时则创建(相当于只做添加)
- 参数:
- name: 缓存名
- key: name对应的hash中的key
- value: name对应的hash中的value
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.hsetnx(name='info', key='age', value='18')
print(r.hgetall('info')) # {'username': 'Kevin', 'age': '18'}
- hmset(name, mapping)
- 在name对应的hash中批量设置键值对
- 参数:
- name: 缓存名
- mapping: 字典,如:{'k1':'v1', 'k2': 'v2'}
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.hmset(name='info', mapping={'username': 'Kevin', 'age': '18'})
print(r.hgetall('info')) # {'age': '18', 'username': 'Kevin'}
- 添加嵌套 hash 的方法
- 方法一:
- 使用 json.dumps 序列化字典
import redis
import json
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.hmset(name='info', mapping={
'username': 'Kevin',
'age': 18,
'address': json.dumps({
'province': '广东省',
'city': '东莞市',
'town': '南城'
})
})
print(r.hgetall('info')) # {'username': 'Kevin', 'address': '{"province": "\\u5e7f\\u4e1c\\u7701", "town": "\\u5357\\u57ce", "city": "\\u4e1c\\u839e\\u5e02"}', 'age': '18'}
json_address = r.hget('info', 'address')
address = json.loads(json_address)
print(address) # {'province': '广东省', 'city': '东莞市', 'town': '南城'}
- 方法二:
- 使用: r.set + json.dumps
import redis
import json
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
info_dic = {
'username': 'Kevin',
'age': 18,
'address': {
'province': '广东省',
'city': '东莞市',
'town': '南城'
}
}
r.set(name='info', value=json.dumps(info_dic))
print(r.get('info')) # {"username": "Kevin", "age": 18, "address": {"town": "\u5357\u57ce", "city": "\u4e1c\u839e\u5e02", "province": "\u5e7f\u4e1c\u7701"'+'}'+'}'}}
json_info = r.get('info')
info = json.loads(json_info)
address = info['address']
print(address) # {'province': '广东省', 'city': '东莞市', 'town': '南城'}
- 错误示范
- 不要直接编写嵌套 hash,因为不是json结构,无法通过 json.loads 解析出来
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.hmset(name='info', mapping={
'username': 'Kevin',
'age': 18,
'address': { # 必须是序列化后的字符串
'province': '广东省',
'city': '东莞市',
'town': '南城'
}
})
- hget(name, key)
- 在name对应的hash中根据key获取value
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 参数:
- name: 缓存名
- key: name对应的hash中的key
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
username = r.hget(name='info', key='username')
print(username) # Kevin
- hmget(name, keys, *args)
- 在name对应的hash中获取多个key所对应的value值(即: 批量获取key的value值)
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 参数:
- name: 缓存名
- keys: key的集合,如: ['k1', 'k2', 'k3']
- *args: keys 打散后的结果,如: k1, k2, k3
- 写法一
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
info_values = r.hmget(name='info', keys=['username', 'age'])
print(info_values) # ['Kevin', '18']
- 写法二
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
info_values = r.hmget('info', 'username', 'age')
print(info_values) # ['Kevin', '18']
- hgetall(name)
- 获取name对应hash的所有键值对
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 参数:
- name: 缓存名
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
info = r.hgetall('info')
print(info) # {'username': 'Kevin', 'age': '18'}
- hlen(name)
- 获取name对应的hash中键值对的个数
- 参数:
- name: 缓存名
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
info_len = r.hlen('info')
print(info_len) # 值: {'username': 'Kevin', 'age': '18'},长度: 2
- hkeys(name)
- 获取name对应的hash中所有的key的值
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 参数:
- name: 缓存名
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
info_keys = r.hkeys('info')
print(info_keys) # ['age', 'username']
- hvals(name)
- 获取name对应的hash中所有的value的值
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 参数:
- name: 缓存名
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
info_values = r.hvals('info')
print(info_values) # ['18', 'Kevin']
- hexists(name, key)
- 检查name对应的hash是否存在当前传入的key
- 参数:
- name: 缓存名
- key: 需要检测的 key 名字
- 返回值: True/False
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
has_key = r.hexists(name='info', key='address')
print(has_key) # 值: {'age': '18', 'username': 'Kevin'},检测结果: False
has_key = r.hexists(name='info', key='username')
print(has_key) # 值: {'age': '18', 'username': 'Kevin'},检测结果: True
- hdel(name, *keys)
- 将name对应的hash中指定key的键值对删除(即: 删除指定的键值对)
- 写法一
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.hdel('info', 'username', 'age')
print(r.hgetall('info')) # 原本的值: {'username': 'Kevin', 'age': '18', 'address': '广东'},删除后的值: {'address': '广东'}
- 写法二
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
del_keys = ['username', 'age']
r.hdel('info', *del_keys)
print(r.hgetall('info')) # 原本的值: {'username': 'Kevin', 'age': '18', 'address': '广东'},删除后的值: {'address': '广东'}
- 将name对应的hash中的键值对清空
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
info_keys = r.hkeys('info') # 获取 info 的所有 key 值
r.hdel('info', *info_keys)
print(r.hgetall('info')) # 原本的值: {'username': 'Kevin', 'age': '18', 'address': '广东'},删除后的值: {}
- hincrby(name, key, amount)
- 整数自增name对应的hash中的指定key的值,当key不存在时,则创建key=amount,否则,进行整数自增
- 需要自增的value必须是整数
- 参数:
- name: 缓存名
- key: name对应的hash中的key
- amount: 每次自增的数量(即: 每次添加的数量),必须是整数
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.hincrby(name='info', key='age', amount=2)
print(r.hgetall('info')) # 原本的值: {'username': 'Kevin', 'age': '18'},自增后的值: {'username': 'Kevin', 'age': '20'}
- hincrbyfloat(name, key, amount)
- 浮点数自增name对应的hash中的指定key的值,当key不存在时,则创建key=amount,否则,进行浮点数自增
- 需要自增的value可以是整数或浮点数
- 参数:
- name: 缓存名
- key: name对应的hash中的key
- amount: 每次自增的数量(即: 每次添加的数量),可以是整数或浮点数
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.hincrbyfloat(name='info', key='age', amount=2.5)
print(r.hgetall('info')) # 原本的值: {'username': 'Kevin', 'age': '20'},自增后的值: {'username': 'Kevin', 'age': '22.5'}
- hscan(name, cursor, match, count)
- 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而防止内存被撑爆
- 当 hash 中的键值对数量过少的时候,hscan 是无效的
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 参数:
- name: 缓存名
- cursor: 游标(基于游标分批取获取数据)
- match: 匹配指定key,默认None 表示所有的key
- count: 每次分片最少获取个数,默认None表示采用redis的默认分片个数
- 返回值:
- 返回值有两个
- 第一个: 游标 -> 当游标为0的时候表示数据以及获取完
- 第二个: 获取到的值
- 说明 hscan 的用法的写法
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
# 写入 1024 条数据
# for i in range(1024):
# r.hmset('info', {
# 'username%s' % i: 'Kevin', 'age%s' % i: '18',
# })
cursor1, data1 = r.hscan('info', cursor=0, match=None, count=None)
print(cursor1, data1) # 1408 {'age873': '18', 'age834': '18', 'username817': 'Kevin', 'age370': '18', 'age49': '18', 'age349': '18', 'age420': '18', 'username647': 'Kevin', 'username309': 'Kevin', 'age25': '18', 'username261': 'Kevin'}
cursor2, data2 = r.hscan('info', cursor=cursor1, match=None, count=None)
print(cursor2, data2) # 1344 {'age880': '18', 'username439': 'Kevin', 'username964': 'Kevin', 'age640': '18', 'age769': '18', 'username807': 'Kevin', 'age478': '18', 'age605': '18', 'username629': 'Kevin', 'age990': '18', 'username457': 'Kevin'}
cursor1, data1 = r.hscan('info', cursor=cursor2, match=None, count=None)
print(cursor1, data1) # 1472 {'username1011': 'Kevin', 'username494': 'Kevin', 'age329': '18', 'username987': 'Kevin', 'age426': '18', 'username927': 'Kevin', 'age993': '18', 'username884': 'Kevin', 'username786': 'Kevin', 'username624': 'Kevin'}
- 实际应用写法
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
# 写入 1024 条数据
# for i in range(1024):
# r.hmset('info', {
# 'username%s' % i: 'Kevin', 'age%s' % i: '18',
# })
cursor = 1
while cursor:
cursor, data = r.hscan('info', cursor=cursor, match=None, count=None)
print(cursor, data)
- hscan_iter(name, match, count)
- hscan_iter利用yield封装hscan创建的生成器,实现分批去redis中获取数据
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 参数:
- name: 缓存名
- match: 匹配指定key,默认None 表示所有的key
- count: 每次分片最少获取个数,默认None表示采用redis的默认分片个数
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
# 写入 1024 条数据
# for i in range(1024):
# r.hmset('info', {
# 'username%s' % i: 'Kevin', 'age%s' % i: '18',
# })
for i in r.hscan_iter('info'):
print(i)
4. Set(集合)类型的操作,不允许有重复数据的列表
- sadd(name, values)
- 在 name 对应的集合中添加元素
- 参数:
- name: 缓存名
- values: 要添加的元素,可以接收多个值
- 写法一
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.sadd('books', '三国演义', '红楼梦', '西游记', '水浒传')
print(r.smembers('books')) # {'红楼梦', '三国演义', '西游记', '水浒传'}
- 写法二
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
books = ['三国演义', '红楼梦', '西游记', '水浒传']
r.sadd('books', *books)
print(r.smembers('books')) # {'红楼梦', '三国演义', '西游记', '水浒传'}
- scard(name)
- 获取name对应的集合中元素个数
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
books_len = r.scard('books')
print(books_len) # 值: {'红楼梦', '三国演义', '西游记', '水浒传'},长度: 4
- sdiff(keys, *args)
- 返回多个集合之间的差集
- 参数:
- keys: 缓存名的集合,如: ['k1', 'k2', 'k3']
- *args: 缓存名的集合打散后的结果,如: k1, k2, k3
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 写法一
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.sadd('library1', '三国演义', '红楼梦', '匆匆那年', '水浒传')
r.sadd('library2', '三国演义', '三体', '西游记', '水浒传')
diff = r.sdiff(['library1', 'library2'])
print(diff) # {'匆匆那年', '红楼梦'}
- 写法二
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.sadd('library1', '三国演义', '红楼梦', '匆匆那年', '水浒传')
r.sadd('library2', '三国演义', '三体', '西游记', '水浒传')
diff = r.sdiff('library1', 'library2')
print(diff) # {'匆匆那年', '红楼梦'}
- sdiffstore(dest, keys, *args)
- 将集合之间的差集存储在指定的集合中,如果指定的集合已存在,则会将其覆盖
- 参数:
- dest: 存储差集的集合名称
- keys:缓存名的集合,如: ['k1', 'k2', 'k3']
- *args: 缓存名的集合打散后的结果,如: k1, k2, k3
- 写法一
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.sadd('library1', '三国演义', '红楼梦', '匆匆那年', '水浒传')
r.sadd('library2', '三国演义', '三体', '西游记', '水浒传')
r.sadd('save_diff', 'testdata')
r.sdiffstore(dest='save_diff', keys=['library1', 'library2'])
print(r.smembers('save_diff')) # {'匆匆那年', '红楼梦'}
- 写法二
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.sadd('library1', '三国演义', '红楼梦', '匆匆那年', '水浒传')
r.sadd('library2', '三国演义', '三体', '西游记', '水浒传')
r.sadd('save_diff', 'testdata')
r.sdiffstore('save_diff', 'library1', 'library2')
print(r.smembers('save_diff')) # {'匆匆那年', '红楼梦'}
- sinter(keys, *args)
- 返回多个集合之间的交集,不存在的集合 key 被视为空集,当给定集合当中有一个空集时,结果也为空集
- 参数:
- keys: 缓存名的集合,如: ['k1', 'k2', 'k3']
- *args: 缓存名的集合打散后的结果,如: k1, k2, k3
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 写法一
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.sadd('library1', '三国演义', '红楼梦', '匆匆那年', '水浒传')
r.sadd('library2', '三国演义', '三体', '西游记', '水浒传')
inter = r.sinter(['library1', 'library2'])
print(inter) # {'三国演义', '水浒传'}
- 写法二
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.sadd('library1', '三国演义', '红楼梦', '匆匆那年', '水浒传')
r.sadd('library2', '三国演义', '三体', '西游记', '水浒传')
inter = r.sinter('library1', 'library2')
print(inter) # {'三国演义', '水浒传'}
- sinterstore(dest, keys, *args)
- 将集合之间的交集存储在指定的集合中,如果指定的集合已存在,则会将其覆盖
- 参数:
- dest: 存储交集的集合名称
- keys:缓存名的集合,如: ['k1', 'k2', 'k3']
- *args: 缓存名的集合打散后的结果,如: k1, k2, k3
- 写法一
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.sadd('library1', '三国演义', '红楼梦', '匆匆那年', '水浒传')
r.sadd('library2', '三国演义', '三体', '西游记', '水浒传')
r.sadd('save_inter', 'testdata')
r.sinterstore(dest='save_inter', keys=['library1', 'library2'])
print(r.smembers('save_inter')) # {'水浒传', '三国演义'}
- 写法二
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.sadd('library1', '三国演义', '红楼梦', '匆匆那年', '水浒传')
r.sadd('library2', '三国演义', '三体', '西游记', '水浒传')
r.sadd('save_inter', 'testdata')
r.sinterstore('save_inter', 'library1', 'library2')
print(r.smembers('save_inter')) # {'水浒传', '三国演义'}
- sunion(keys, *args)
- 返回多个集合之间的并集,不存在的集合 key 被视为空集,当给定集合当中有一个空集时,结果也为空集
- 参数:
- keys: 缓存名的集合,如: ['k1', 'k2', 'k3']
- *args: 缓存名的集合打散后的结果,如: k1, k2, k3
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 写法一
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.sadd('library1', '三国演义', '红楼梦', '匆匆那年', '水浒传')
r.sadd('library2', '三国演义', '三体', '西游记', '水浒传')
union = r.sunion(['library1', 'library2'])
print(union) # {'三国演义', '水浒传', '匆匆那年', '三体', '红楼梦', '西游记'}
- 写法二
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.sadd('library1', '三国演义', '红楼梦', '匆匆那年', '水浒传')
r.sadd('library2', '三国演义', '三体', '西游记', '水浒传')
union = r.sunion('library1', 'library2')
print(union) # {'三国演义', '水浒传', '匆匆那年', '三体', '红楼梦', '西游记'}
- sunionstore(dest, keys, *args)
- 将集合之间的并集存储在指定的集合中,如果指定的集合已存在,则会将其覆盖
- 参数:
- dest: 存储并集的集合名称
- keys:缓存名的集合,如: ['k1', 'k2', 'k3']
- *args: 缓存名的集合打散后的结果,如: k1, k2, k3
- 写法一
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.sadd('library1', '三国演义', '红楼梦', '匆匆那年', '水浒传')
r.sadd('library2', '三国演义', '三体', '西游记', '水浒传')
r.sadd('save_union', 'testdata')
r.sunionstore(dest='save_union', keys=['library1', 'library2'])
print(r.smembers('save_union')) # {'匆匆那年', '水浒传', '三国演义', '三体', '西游记', '红楼梦'}
- 写法二
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.sadd('library1', '三国演义', '红楼梦', '匆匆那年', '水浒传')
r.sadd('library2', '三国演义', '三体', '西游记', '水浒传')
r.sadd('save_union', 'testdata')
r.sunionstore('save_union', 'library1', 'library2')
print(r.smembers('save_union')) # {'匆匆那年', '水浒传', '三国演义', '三体', '西游记', '红楼梦'}
- sismember(name, value)
- 检查value是否是name对应的集合的成员
- 参数:
- name: 缓存名
- value: 需要检测的值
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
is_has = r.sismember(name='info', value='三国演义')
print(is_has) # 值: {'三国演义', '红楼梦', '水浒传', '西游记'},检测后的结果: True
- smove(src, dst, value)
- 将某个成员从一个集合中移动到另外一个集合
- 参数:
- src: 要取数据的集合的name
- dst: 要添加数据的集合的name
- value: 要取的数据
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.sadd('library1', '三国演义', '红楼梦', '匆匆那年', '水浒传')
r.sadd('library2', '三国演义', '三体', '西游记', '水浒传')
r.smove(src='library1', dst='library2', value='匆匆那年')
print(r.smembers('library1')) # {'三国演义', '红楼梦', '水浒传'}
print(r.smembers('library2')) # {'三国演义', '匆匆那年', '三体', '西游记', '水浒传'}
- spop(name)
- 删除集合中的最后一个成员,并将其返回
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
del_data = r.spop('books')
print(del_data) # 西游记
- srandmember(name, numbers)
- 从 name 对应的集合中随机获取 numbers 个元素
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 参数:
- name: 缓存名
- numbers: 获取集合的成员个数
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.sadd('books', '三国演义', '红楼梦', '水浒传', '西游记')
random_book = r.srandmember(name='books', number=3)
print(random_book) # ['红楼梦', '水浒传', '三国演义']
- srem(name, values)
- 移除集合中的一个或多个成员元素,不存在的成员元素会被忽略
- 参数:
- name: 缓存名
- values: 要移除的元素,可以接收多个值
- 写法一
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.srem('books', '红楼梦', '水浒传')
print(r.smembers('books')) # 原本的值: {'三国演义', '红楼梦', '水浒传', '西游记'},删除后的值: {'三国演义', '西游记'}
- 写法二
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
books = ['红楼梦', '水浒传']
r.srem('books', *books)
print(r.smembers('books')) # 原本的值: {'三国演义', '红楼梦', '水浒传', '西游记'},删除后的值: {'三国演义', '西游记'}
- sscan(name, cursor, match, count)
- 增量式迭代获取,对于数据大的数据非常有用,sscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而防止内存被撑爆
- 当集合中的成员数量过少的时候,sscan 是无效的
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 参数:
- name: 缓存名
- cursor: 游标(基于游标分批取获取数据)
- match: 匹配指定key,默认None 表示所有的key
- count: 每次分片最少获取个数,默认None表示采用redis的默认分片个数
- 返回值:
- 返回值有两个
- 第一个: 游标 -> 当游标为0的时候表示数据以及获取完
- 第二个: 获取到的值
- 说明 sscan 的用法的写法
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
# 写入 1024 条数据
# for i in range(1024):
# r.sadd('set_list', '数据%s' % i)
cursor1, data1 = r.sscan('set_list', cursor=0, match=None, count=None)
print(cursor1, data1) # 896 ['数据235', '数据1002', '数据148', '数据719', '数据418', '数据754', '数据385', '数据715', '数据849', '数据1001']
cursor2, data2 = r.sscan('set_list', cursor=cursor1, match=None, count=None)
print(cursor2, data2) # 928 ['数据161', '数据976', '数据554', '数据126', '数据258', '数据328', '数据112', '数据707', '数据533', '数据115']
cursor1, data1 = r.sscan('set_list', cursor=cursor2, match=None, count=None)
print(cursor1, data1) # 272 ['数据947', '数据721', '数据335', '数据127', '数据965', '数据79', '数据870', '数据455', '数据681', '数据307', '数据933']
- 实际应用写法
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
# 写入 1024 条数据
# for i in range(1024):
# r.sadd('set_list', '数据%s' % i)
cursor = 1
while cursor:
cursor, data = r.sscan('set_list', cursor=cursor, match=None, count=None)
print(cursor, data)
- sscan_iter(name, match, count)
- sscan_iter利用yield封装sscan创建的生成器,实现分批去redis中获取数据
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 参数:
- name: 缓存名
- match: 匹配指定key,默认None 表示所有的key
- count: 每次分片最少获取个数,默认None表示采用redis的默认分片个数
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
# 写入 1024 条数据
# for i in range(1024):
# r.sadd('set_list', '数据%s' % i)
for i in r.sscan_iter('set_list'):
print(i)
5. Sorted Set(有序集合)类型的操作
- 有序集合:
- 在集合的基础上,为每元素排序;
- 元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序
- zadd(name, mapping, nx, xx, ch, incr)
- 在name对应的有序集合中添加元素
- 参数:
- name: 缓存名
- mapping: 字典,如 {'值': 分数} -> {'value': 1}
- nx: 如果值为 True,当 name 不存在的时候,当前set操作才会执行
- xx: 如果值为 True,当 name 存在的时候,当前set操作才会执行
- ch: 如果值为 True,那么返回值就是添加或修改了多少个元素的个数
- incr: 自增(+1),如果值为True,那么就会对某一个元素的分数自加1,且返回值是该元素的分数自加1的结果,并且 mapping 参数只能有一个键值对
- 一般的使用
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.zadd(name='s_set', mapping={'n1': 1, 'n2': 2, 'n3': 3}) # 根据分数进行排序,且 value 就是分数,key就是有序集合的值
print(r.zrange('s_set', 0, -1, withscores=True)) # [('n1', 1.0), ('n2', 2.0), ('n3', 3.0)]
- ch=True
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
add_num = r.zadd(name='s_set', mapping={'n1': 1, 'n2': 2, 'n3': 3, 'n4': 4, 'n5': 5}, ch=True)
print(add_num) # 2
- incr=True
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
add_num = r.zadd(name='s_set', mapping={'n1': 1}, incr=True)
print(r.zrange('s_set', 0, -1, withscores=True)) # 原本的值: [('n1', 1.0), ('n2', 2.0), ('n3', 3.0)],当 incr=True 并且执行2次后: [('n2', 2.0), ('n1', 3.0), ('n3', 3.0)]
- zcard(name)
- 获取name对应的有序集合元素的数量
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
s_set_len = r.zcard('s_set')
print(s_set_len) # 值: [('n1', 1.0), ('n2', 2.0), ('n3', 3.0)],长度: 3
- zcount(name, min, max)
- 获取在 min-max 范围分数的个数
- 参数:
- name: 缓存名
- min: 分数最小值
- max: 分数最大值
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
fraction_len = r.zcount(name='s_set', min=2, max=4)
print(fraction_len) # 值: [('n1', 1.0), ('n2', 2.0), ('n3', 3.0), ('n4', 4.0), ('n5', 5.0)],长度: 3
- zincrby(name, value, amount)
- 自增name对应的有序集合的 value 对应的分数
- 参数:
- name: 缓存名
- value: 需要自增分数的value
- amount: 每次自增的数量(即: 每次添加的数量),必须是整数
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.zincrby(name='s_set', value='n1', amount=2) # 当前 n1 的分数为 1,自增后 n1 的分数为 3
print(r.zrange('s_set', 0, -1, withscores=True)) # 没有自增前的值: [('n1', 1.0), ('n2', 2.0), ('n3', 3.0)],自增后的值: [('n2', 2.0), ('n1', 3.0), ('n3', 3.0)]
- r.zrange(name, start, end, desc, withscores, score_cast_func)
- 切片 + 排序 + 分数的显示
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 参数:
- name: 缓存名
- start: 有序集合索引起始位置(非分数)
- end: 有序集合索引结束位置(非分数)
- desc: 如果值True,那么就按照分数的降序排序,否则按照分数升序排序
- withscores: 是否获取元素的分数,默认只获取元素的值
- score_cast_func: 对分数进行数据转换的函数,默认使用的函数是 float,可以修改为 int
- 基本使用
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.zadd(name='s_set', mapping={'n1': 1, 'n2': 2, 'n3': 3, 'n4': 4, 'n5': 5})
s_set = r.zrange(name='s_set', start=1, end=3, desc=True, withscores=True, score_cast_func=int)
print(s_set) # [('n4', 4), ('n3', 3), ('n2', 2)]
- 获取有序集合的所有数据
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.zadd(name='s_set', mapping={'n1': 1, 'n2': 2, 'n3': 3, 'n4': 4, 'n5': 5})
s_set = r.zrange(name='s_set', start=0, end=-1, withscores=True, score_cast_func=int)
print(s_set) # [('n1', 1), ('n2', 2), ('n3', 3), ('n4', 4), ('n5', 5)]
- zrank(name, value)
- 获取某个值在name对应的有序集合中的排行(先进行从小到大的排序,然后在进行获取) -> 从 0 开始算起
- 参数
- name: 缓存名
- value: 需要获取排行的值
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
rank = r.zrank(name='s_set', value='n2')
print(rank) # 有序集合的值: [('n1', 1), ('n2', 2), ('n3', 3), ('n4', 4), ('n5', 5)],n2 的排行: 1
- zrevrank(name, value)
- 获取某个值在name对应的有序集合中的排行(先进行从大到小的排序,然后在进行获取) -> 从 0 开始算起
- 参数
- name: 缓存名
- value: 需要获取排行的值
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
rank = r.zrevrank(name='s_set', value='n2')
print(rank) # 有序集合的值: [('n1', 1), ('n2', 2), ('n3', 3), ('n4', 4), ('n5', 5)],n2 的排行: 3
- zrangebylex(name, min, max, start, num)
# 当有序集合的所有成员都具有相同的分值时,有序集合的元素会根据成员的 值 (lexicographical ordering)来进行排序,而这个命令则可以返回给定的有序集合键 key 中, 元素的值介于 min 和 max 之间的成员
# 对集合中的每个成员进行逐个字节的对比(byte-by-byte compare), 并按照从低到高的顺序, 返回排序后的集合成员。 如果两个字符串有一部分内容是相同的话, 那么命令会认为较长的字符串比较短的字符串要大
# 参数:
# name,redis的name
# min,左区间(值)。 + 表示正无限; - 表示负无限; ( 表示开区间; [ 则表示闭区间
# min,右区间(值)
# start,对结果进行分片处理,索引位置
# num,对结果进行分片处理,索引后面的num个元素
# 如:
# ZADD myzset 0 aa 0 ba 0 ca 0 da 0 ea 0 fa 0 ga
# r.zrangebylex('myzset', "-", "[ca") 结果为:['aa', 'ba', 'ca']
# 更多:
# 从大到小排序
# zrevrangebylex(name, max, min, start=None, num=None)
- zrem(name, values)
- 移除有序集中的一个或多个成员,不存在的成员将被忽略
- 参数:
- name: 缓存名
- values: 要移除的元素,可以接收多个值
- 写法一
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.zrem('s_set', 'n2', 'n3', 'n4')
print(r.zrange('s_set', 0, -1, withscores=True, score_cast_func=int)) # 未移除任何元素前的值: [('n1', 1), ('n2', 2), ('n3', 3), ('n4', 4), ('n5', 5)],移除某些元素后的值: [('n1', 1), ('n5', 5)]
- 写法二
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r_s_set = ['n2', 'n3', 'n4']
r.zrem('s_set', *r_s_set)
print(r.zrange('s_set', 0, -1, withscores=True, score_cast_func=int)) # 未移除任何元素前的值: [('n1', 1), ('n2', 2), ('n3', 3), ('n4', 4), ('n5', 5)],移除某些元素后的值: [('n1', 1), ('n5', 5)]
- zremrangebyrank(name, min, max)
- 删除在 min-max 范围排行内的成员 -> (从大到小的排序,从0开始算起)
- 参数:
- name: 缓存名
- min: 最小排行数
- max: 最大排行树
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.zadd(name='s_set', mapping={'n1': 1, 'n2': 2, 'n3': 3, 'n4': 4, 'n5': 5})
r.zremrangebyrank(name='s_set', min=1, max=3)
print(r.zrange('s_set', 0, -1, withscores=True, score_cast_func=int)) # [('n1', 1), ('n5', 5)]
- zremrangebyscore(name, min, max)
- 删除在 min-max 范围分数内的成员 -> (从大到小的排序,从1开始算起)
- 参数:
- name: 缓存名
- min: 最小分数
- max: 最大分树
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.zadd(name='s_set', mapping={'n1': 1, 'n2': 2, 'n3': 3, 'n4': 4, 'n5': 5})
r.zremrangebyscore(name='s_set', min=1, max=3)
print(r.zrange('s_set', 0, -1, withscores=True, score_cast_func=int)) # [('n4', 4), ('n5', 5)]
- zremrangebylex(name, min, max)
# 根据值返回删除
- zscore(name, value)
- 获取name对应有序集合中 value 对应的分数
- 参数:
- name: 缓存名
- value: 要获取分数的value值
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
fraction = r.zscore(name='s_set', value='n3')
print(fraction) # 3.0
- zinterstore(dest, keys, aggregate)
- 将有序集合之间的交集存储在指定的有序集合中,如果指定的有序集合已存在,则会将其覆盖,如果遇到相同值不同分数,则按照aggregate进行操作
- 参数:
- dest: 指定的有序集合
- keys: 缓存名的集合,如: ['k1', 'k2', 'k3']
- aggregate: SUM MIN MAX
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.zadd(name='library1', mapping={'book1_1': 1, 'book': 2, 'book1_3': 3})
r.zadd(name='library2', mapping={'book2_1': 1, 'book': 2, 'book2_3': 3})
r.zinterstore(dest='l_boos', keys=['library1', 'library2'])
print(r.zrange('l_boos', 0, -1, withscores=True, score_cast_func=int)) # [('book', 4)]
- zunionstore(dest, keys, aggregate)
- 将有序集合之间的并集存储在指定的有序集合中,如果指定的有序集合已存在,则会将其覆盖,如果遇到相同值不同分数,则按照aggregate进行操作
- 参数:
- dest: 指定的有序集合
- keys: 缓存名的集合,如: ['k1', 'k2', 'k3']
- aggregate: SUM MIN MAX
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.zadd(name='library1', mapping={'book1_1': 1, 'book': 2, 'book1_3': 3})
r.zadd(name='library2', mapping={'book2_1': 1, 'book': 2, 'book2_3': 3})
r.zunionstore(dest='l_boos', keys=['library1', 'library2'])
print(r.zrange('l_boos', 0, -1, withscores=True, score_cast_func=int)) # [('book1_1', 1), ('book2_1', 1), ('book1_3', 3), ('book2_3', 3), ('book', 4)]
- zscan(name, cursor, match, count, score_cast_func)
- 增量式迭代获取,对于数据大的数据非常有用,zscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而防止内存被撑爆
- 当有序集合中的成员数量过少的时候,zscan 是无效的
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 参数:
- name: 缓存名
- cursor: 游标(基于游标分批取获取数据)
- match: 匹配指定key,默认None 表示所有的key
- count: 每次分片最少获取个数,默认None表示采用redis的默认分片个数
- score_cast_func: 对分数进行数据转换的函数,默认使用的函数是 float,可以修改为 int
- 返回值:
- 返回值有两个
- 第一个: 游标 -> 当游标为0的时候表示数据以及获取完
- 第二个: 获取到的值
- 说明 zscan 的用法的写法
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
# 写入 1024 条数据
# for i in range(1024):
# r.zadd('library', {
# 'book_%s' % i: i
# })
cursor1, data1 = r.zscan('library', cursor=0, match=None, count=None, score_cast_func=int)
print(cursor1, data1) # 64 [('book_1012', 1012), ('book_554', 554), ('book_532', 532), ('book_415', 415), ('book_335', 335), ('book_313', 313), ('book_162', 162), ('book_42', 42), ('book_41', 41), ('book_111', 111), ('book_121', 121)]
cursor2, data2 = r.zscan('library', cursor=cursor1, match=None, count=None, score_cast_func=int)
print(cursor2, data2) # 160 [('book_323', 323), ('book_236', 236), ('book_876', 876), ('book_675', 675), ('book_625', 625), ('book_549', 549), ('book_359', 359), ('book_285', 285), ('book_143', 143), ('book_814', 814), ('book_345', 345), ('book_130', 130)]
cursor1, data1 = r.zscan('library', cursor=cursor2, match=None, count=None, score_cast_func=int)
print(cursor1, data1) # 224 [('book_976', 976), ('book_905', 905), ('book_553', 553), ('book_284', 284), ('book_138', 138), ('book_6', 6), ('book_737', 737), ('book_445', 445), ('book_411', 411), ('book_139', 139)]
- 实际应用写法
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
# 写入 1024 条数据
# for i in range(1024):
# r.zadd('library', {
# 'book_%s' % i: i
# })
cursor = 1
while cursor:
cursor, data = r.zscan('library', cursor=cursor, match=None, count=None, score_cast_func=int)
print(cursor, data)
- zscan_iter(name, match, count, score_cast_func)
- zscan_iter利用yield封装zscan创建的生成器,实现分批去redis中获取数据
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 参数:
- name: 缓存名
- match: 匹配指定key,默认None 表示所有的key
- count: 每次分片最少获取个数,默认None表示采用redis的默认分片个数
- score_cast_func: 对分数进行数据转换的函数,默认使用的函数是 float,可以修改为 int
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
# 写入 1024 条数据
# for i in range(1024):
# r.zadd('library', {
# 'book_%s' % i: i
# })
for i in r.zscan_iter('library'):
print(i)
6. 其他常用方法
- delete(*names)
- 删除一个或多个已存在的任意数据类型缓存,不存在则会被忽略
- 删除一个任意数据类型缓存
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.delete('info')
- 删除多个数据类型缓存
- 写法一
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.delete('info', 'str_data')
- 写法二
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
names = ['info', 'str_data']
r.delete(*names)
- 删除全部的数据类型缓存
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.delete(*r.keys())
- flushall()
- 清空所有缓存
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.flushall()
- exists(name)
- 检测缓存名是否存在
- 返回值:
- 0 -> 不存在
- 1 -> 存在
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
isHas = r.exists('info')
print(isHas) # 1
- keys(pattern)
- 根据 pattern 参数获取缓存名(即: 缓存key),如果 pattern 不传值,默认获取所有缓存名(即: 缓存key)
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 参数:
- pattern: 相当于一个简单的正则
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
# * -> 获取所有缓存名
# r.keys(pattern='*')
# 等价于
print(r.keys()) # ['hxllo', 'hbbbllo', 's_key3', 'hallo', 'hdddllo', 's_key2', 's_key1', 'hello']
# -----------------------------------------------
# xxx?xxx -> ? 0个或1个
print(r.keys(pattern='h?llo')) # ['hxllo', 'hallo', 'hello']
print(r.keys(pattern='s_key?')) # ['s_key3', 's_key2', 's_key1']
# -----------------------------------------------
# xxx*xxx -> * 多个
print(r.keys(pattern='h*llo')) # ['hxllo', 'hbbbllo', 'hallo', 'hdddllo', 'hello']
# -----------------------------------------------
# xxx[]xxx -> 区域匹配
print(r.keys(pattern='h[ae]llo')) # ['hallo', 'hello']
- expire(name, time)
- 给某一个缓存设置或修改超时时间 -> list, hash, set, sorted set 可以通过该方法设置超时时间
- 参数:
- name: 缓存名
- time: 超时时间(单位: 秒)
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.hmset('info', {'username': 'Kevin', 'age': 18})
r.expire(name='info', time=10)
- rename(src, dst)
- 重命名缓存名
- 参数:
- src: 需要重命名的缓存名
- dst: 新的缓存名
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.hmset('info', {'username': 'Kevin', 'age': 18})
r.rename(src='info', dst='user_info')
print(r.hgetall('info')) # {}
print(r.hgetall('user_info')) # {'age': '18', 'username': 'Kevin'}
- move(name, db)
- 将redis的某个值移动到指定的db下
- 将当前数据库的 key 移动到给定的数据库 db 当中,select可以设定当前的数据库,如有需要请看select命令因为我们默认使用的数据库是db0,我们可以使用下面的命令键 2 移动到数据库 1 中去
r.move(2,1)
- randomkey()
- 随机获取一个缓存名
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
redis_name = r.randomkey()
print(redis_name) # user_info
- type(name)
- 获取指定缓存名所对应值的类型
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
r_type = r.type('user_info')
print(r_type) # hash
- scan(cursor, match, count)
- 增量式迭代获取缓存名,对于数据大的数据非常有用,scan可以实现分片的获取数据,并非一次性将数据全部获取完,从而防止内存被撑爆
- 当缓存中的缓存名数量过少的时候,scan 是无效的
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 参数:
- cursor: 游标(基于游标分批取获取数据)
- match: 匹配指定key,默认None 表示所有的key
- count: 每次分片最少获取个数,默认None表示采用redis的默认分片个数
- 返回值:
- 返回值有两个
- 第一个: 游标 -> 当游标为0的时候表示数据以及获取完
- 第二个: 获取到的值
- 说明 scan 的用法的写法
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
# 写入 1024 条数据
# for i in range(1024):
# r.set('book_name%s' % i, 'book_%s' % i)
cursor1, data1 = r.scan(cursor=0, match=None, count=None)
print(cursor1, data1) # 640 ['book_name633', 'book_name239', 'book_name180', 'book_name177', 'book_name464', 'book_name798', 'book_name193', 'book_name110', 'book_name972', 'book_name597']
cursor2, data2 = r.scan(cursor=cursor1, match=None, count=None)
print(cursor2, data2) # 192 ['book_name694', 'book_name623', 'book_name305', 'book_name1014', 'book_name885', 'book_name808', 'book_name434', 'book_name10', 'book_name461', 'book_name454']
cursor1, data1 = r.scan(cursor=cursor2, match=None, count=None)
print(cursor1, data1) # 672 ['book_name296', 'book_name322', 'book_name774', 'book_name721', 'book_name440', 'book_name674', 'book_name256', 'book_name204', 'book_name493', 'book_name18']
- 实际应用写法
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
# 写入 1024 条数据
# for i in range(1024):
# r.set('book_name%s' % i, 'book_%s' % i)
cursor = 1
while cursor:
cursor, data = r.scan(cursor=cursor, match=None, count=None)
print(cursor, data)
- scan_iter(match=None, count=None)
- scan_iter利用yield封装scan创建的生成器,实现分批去redis中获取数据
- decode_responses 参数的问题和 get(name) 方法一样(这里就不做演示了)
- 参数:
- match: 匹配指定key,默认None 表示所有的key,可以和keys方法一样支持模糊查询
- count: 每次分片最少获取个数,默认None表示采用redis的默认分片个数
import redis
pool = redis.ConnectionPool(decode_responses=True)
r = redis.Redis(connection_pool=pool)
# 写入 1024 条数据
# for i in range(1024):
# r.set('book_name%s' % i, 'book_%s' % i)
# 获取所有缓存名
for i in r.scan_iter():
print(i)
# -----------------------------------------------
# xxx?xxx -> ? 0个或1个
# for i in r.scan_iter(match='h?llo'):
# 等同于
for i in r.scan_iter('h?llo'):
print(i) # 'hxllo', 'hallo', 'hello'
# for i in r.scan_iter(match='s_key?'):
# 等同于
for i in r.scan_iter('s_key?'):
print(i) # 's_key3', 's_key2', 's_key1'
# -----------------------------------------------
# xxx*xxx -> * 多个
# for i in r.scan_iter(match='h*llo'):
# 等同于
for i in r.scan_iter('h*llo'):
print(i) # 'hxllo', 'hbbbllo', 'hallo', 'hdddllo', 'hello'
# -----------------------------------------------
# xxx[]xxx -> 区域匹配
# for i in r.scan_iter(match='h[ae]llo'):
# 等同于
for i in r.scan_iter('h[ae]llo'):
print(i) # 'hallo', 'hello'